最近、生成モデルを利用して何か作ってみようかと、生成モデルを学んでいます。 今回は最も基本的な敵対的生成ネットワーク(GAN)の基本的な仕組みについて説明します。
GANとは生成モデルの一種であるため、まずは生成モデルについて説明します。
生成モデルとは
生成モデルとは、写真やイラスト、音楽など実際のデータそのものを出力することができる機械学習モデルです。
機械学習では、画像にうつっているものを識別したり、真偽を判定したりと、未来数値の変化を予測したりといった用途でよく利用されています。
画像の分類などを行うモデルは識別モデルと呼ばれていて、2値分類の場合は、分類ラベルを表す「0」、「1」となります。
生成モデルはこれらのモデルとは異なり、入力はランダムなベクトルをとり、出力は画像などのデータそのものとなります。
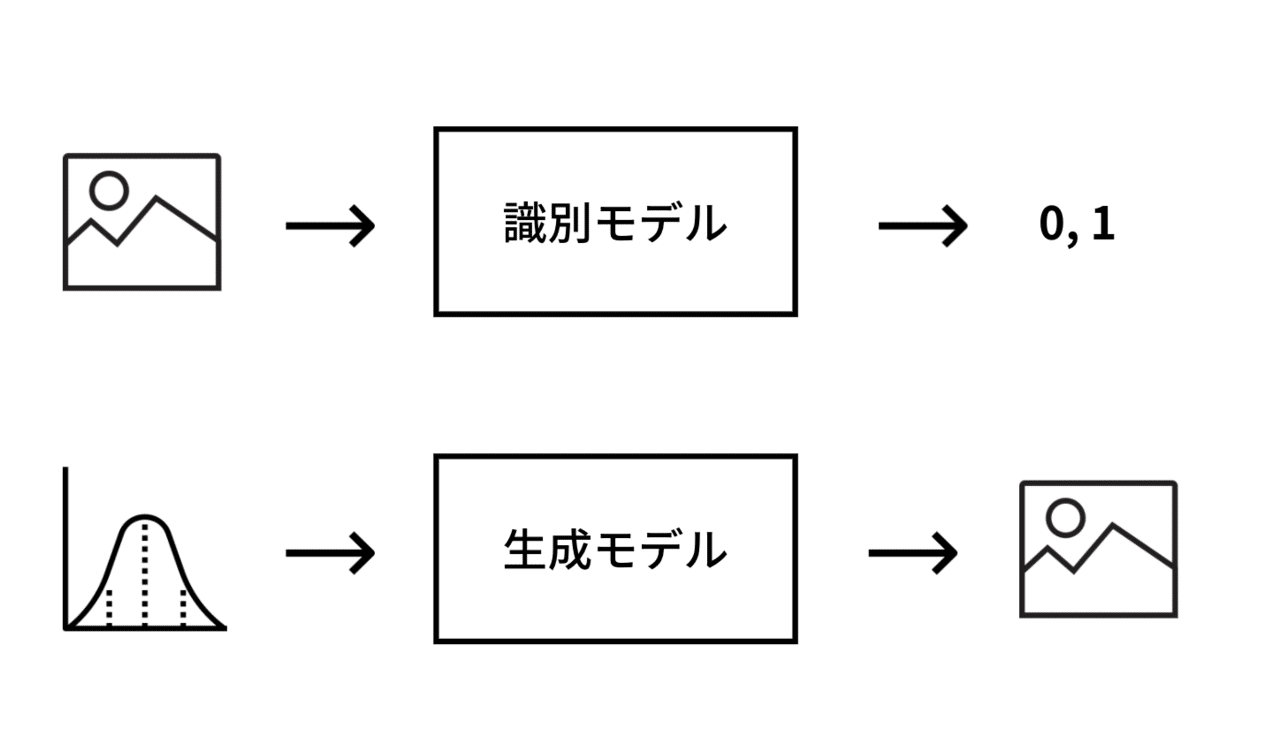
機械によって存在しないデータを作り出すことができる、まさに人工知能的な技術といえると思います。
敵対的生成ネットワーク(GAN)とは
生成モデルの中で、近年成功を収めている手法が、敵対的生成ネットワーク(GAN)です。
現在成功をおさめているGANは生成モデルに深層学習技術を利用しており、従来よりも精度の高い出力を可能にしました。
たとえば、こちらはGANの一種のStyleGANという手法で生成した画像ですが、 かなり写真に近い画像を生成することができています。

GANの基本
GANはデータを作り出す生成モデルと本物と偽物を見分ける識別モデルの2つを組み合わせて学習を行います。
識別モデルは生成モデルのデータ(ラベル: 0)と本物のデータ(ラベル: 1)を使って学習を行います。学習を行うことで識別モデルはデータが本物か偽物かを見分けられるようになります。
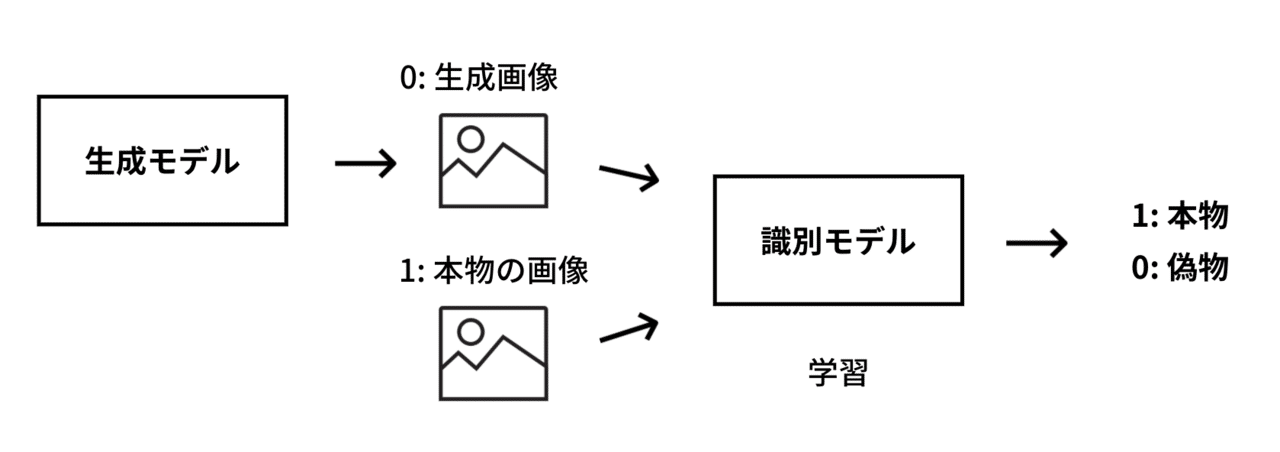
生成モデルはランダムな数値ベクトルを入力として、出力を行いますが、学習時は識別モデルと連結し、 識別モデルの出力が本物と判定されるように生成モデルの学習を行います。 つまり、生成モデルは後段の識別モデルが本物の画像だと間違えてしまう画像を作るように学習します。
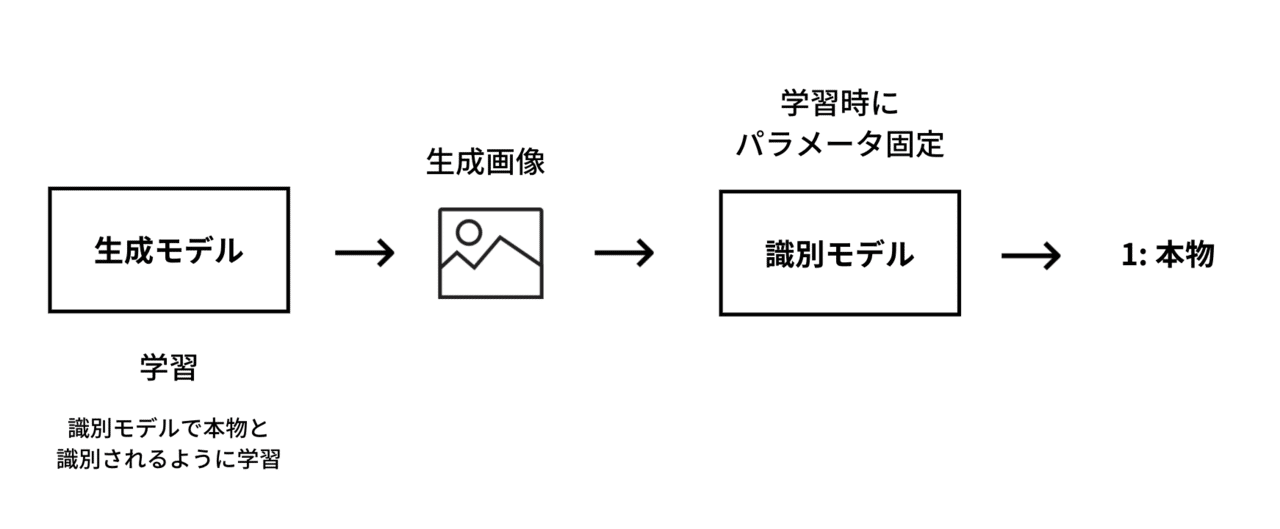
生成モデルの学習時に注意が必要なのは、識別モデルのパラメータは変更しないことです。 識別モデルは忖度せずに厳しく判定を行なってほしいですが、学習時に識別モデルを変化させてしまうと、 入力画像が似ていなくても本物と識別してしまう弱い識別モデルになってしまいます。
TensorFlowを使ったGANの実装
今回はTensorFlowを使ってGAN(DCGAN)を実装してみたいと思います。 GANの学習は時間がかかるため、GPUが利用できる環境で実行したほうが良いです。 今回は無料でGPUが利用できるGoogleのColaboratory で学習を行います。
- (1) データの読み込み
- (2) 生成器の作成
- (3) 識別器の作成
- (4) モデルのコンパイル
- (5) モデルの学習
の順に説明します。実際に動かしたコードはこちらで公開しています。
(1) データの読み込み
TensorFlowのパッケージに付属するmnistのデータを利用して学習を行ってみます。 データのshapeは「(60000, 28, 28)」で返ってきますが、モデルへの入力を「(28, 28, 1)」にしたいため「reshape」します。
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(-1, 28, 28, 1)
x_test = x_test.reshape(-1, 28, 28, 1)また、このデータは「0~255」まで整数を取りますが、入力値を適切にスケーリングしないと上手く学習できないため、 「-1 ~ 1」の範囲を取るように変換します。
x_train = (x_train - 127.5) / 127.5
x_test = (x_test - 127.5) / 127.5(2) 生成器の作成
KerasのFunctional APIを利用してモデルを作成します。まずモデルで利用するパッケージをimportします。
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, \
Dense, Conv2D, LeakyReLU, BatchNormalization, \
Reshape, UpSampling2D, Activation後で利用する定数を定義します。
kernel_size はモデルの畳み込み層で利用するカーネルサイズです。
noize_vector_dim は生成モデルの入力ベクトルのサイズです。
kernel_size = 5
noize_vector_dim = 100今回は最終的に 28 x 28 のサイズの画像を作成したいため、 アップサンプリング層 で倍々に増やしたときに、
ちょうど28となるように最初の畳み込み層への入力サイズを決めます。
アップサンプリング層は、行と列を繰り返してサイズを大きくする層です。 参考: https://keras.io/api/layers/reshaping_layers/up_sampling2d/
7 x 7とした場合、 7 x 7 → 14 x 14 → 28 x 28 となるため、
最初のサイズは 7 x 7 x N とします。今回は N = 64 としました。
input_layer = Input(shape=(noize_vector_dim,))
x = Dense(units=7*7*64)(input_layer)
x = BatchNormalization(momentum=0.8)(x)
x = Reshape(target_shape=(7, 7, 64))(x)アップサンプリング層、畳み込み層、バッチ正規化層、活性化層を順に適用し繰り返します。
x = UpSampling2D()(x)
x = Conv2D(filters=128, strides=1,
kernel_size=kernel_size, padding='same')(x)
x = BatchNormalization(momentum=0.8)(x)
x = LeakyReLU()(x)
x = Conv2D(filters=64, strides=1,
kernel_size=kernel_size, padding='same')(x)
x = BatchNormalization(momentum=0.8)(x)
x = LeakyReLU()(x)
x = Conv2D(filters=64, strides=1,
kernel_size=kernel_size, padding='same')(x)
x = BatchNormalization(momentum=0.8)(x)
x = LeakyReLU()(x)バッチ正規化層を入れると学習が安定することが知られています。
最後に畳み込み層のフィルタの数を1にして、 (28 x 28 x 1) の出力にします。
最後に tanh を活性化関数とします。これにより出力が -1 ~ 1 の範囲を取るようになります。
DCGANの論文では、全ての層で正規化層を入れるとモデルが不安定になるため、 生成器の出力層ではバッチ正規化を行っておらず、ここでも正規化層を入れていないです。 参考: https://arxiv.abs/1511.06434
x = Conv2D(filters=1, strides=1,
kernel_size=kernel_size, padding='same')(x)
output_layer = Activation("tanh")(x)入力層と出力層を Model に渡し、生成器を作成します。
generative_model = Model(input_layer, output_layer)modelのサマリーは以下のようになります。
generative_model.summary()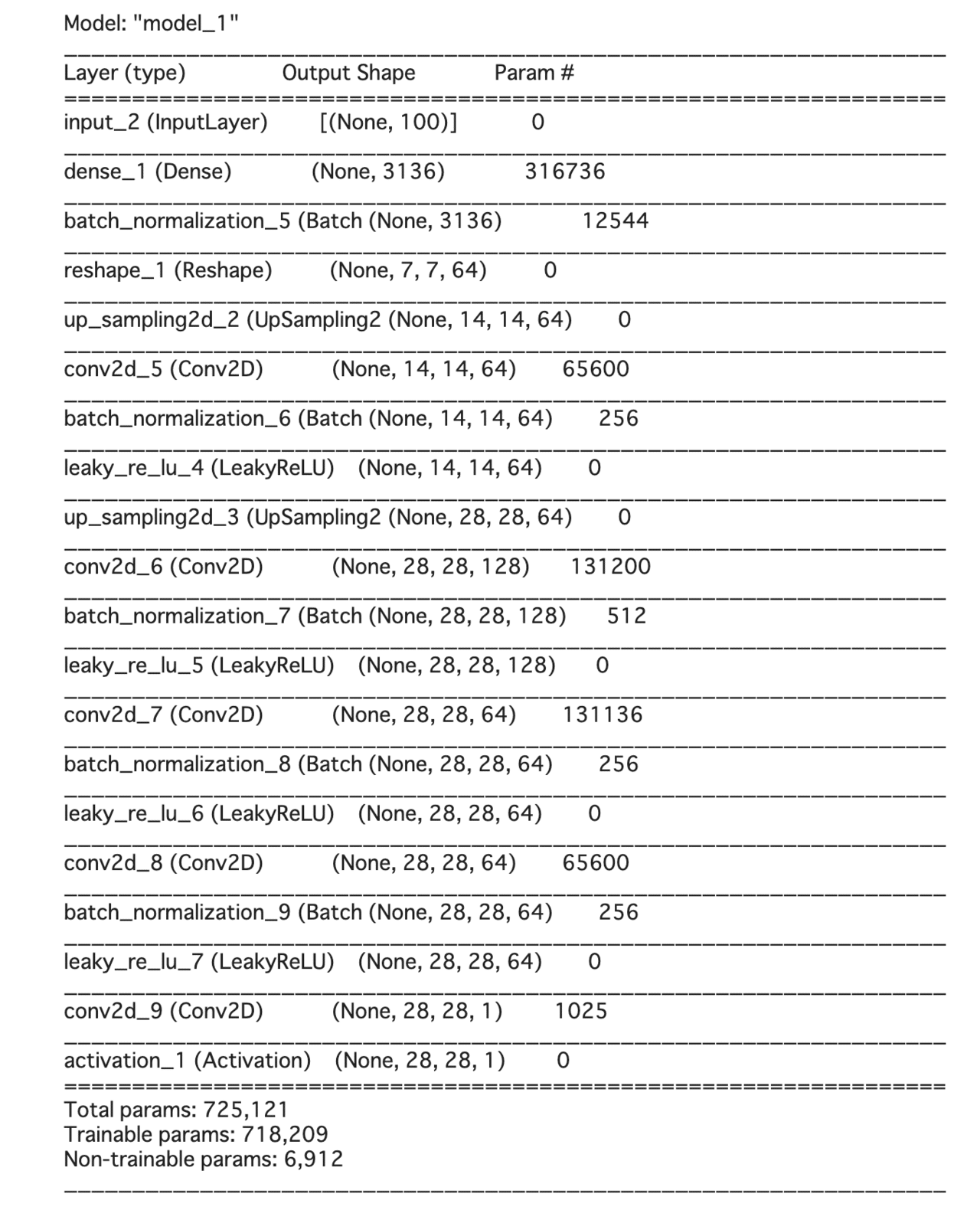
(3) 識別器の作成
識別用のモデルは、畳み込み層と活性化層、ドロップアウト層で構成します。 出力層の手前で平坦化層で平坦化し、出力層はシグモイド関数を使って0~1の範囲で出力を行います。
DCGANの論文 では識別器でも入力層以外はバッチ正規化を入れていたようですが、一般に識別器では利用しない方が良いようです。
識別器の学習ではバッチ正規化は本物のバッチと偽物のバッチでパラメータを決定しますが、 生成器では全て偽物のバッチの正規化となってしまい、学習がうまくいかなくなるようです。 (こちらのコメントを参考 )
識別器では、学習の安定化のためにドロップアウト層を利用します。
kernel_size = 5
input_layer = Input(shape=(28, 28, 1))
x = Conv2D(filters=64, strides=2, kernel_size=kernel_size, padding='same')(input_layer)
x = LeakyReLU()(x)
x = Conv2D(filters=64, strides=2, kernel_size=kernel_size, padding='same')(x)
x = LeakyReLU()(x)
x = Dropout(rate=0.3)(x)
x = Conv2D(filters=128, strides=2, kernel_size=kernel_size, padding='same')(x)
x = LeakyReLU()(x)
x = Dropout(rate=0.4)(x)
x = Conv2D(filters=128, strides=1, kernel_size=kernel_size, padding='same')(x)
x = LeakyReLU()(x)
x = Dropout(rate=0.4)(x)
x = Flatten()(x)
output_layer = Dense(units=1, activation='sigmoid')(x)
discriminator_model = Model(input_layer, output_layer)モデルのサマリーは以下のようになります。
discriminator_model.summary()
(4) モデルのコンパイル
まず識別器のコンパイルを行います。識別器は2値分類を行うため、損失に binary_crossentropy を指定します。
discriminator_model.compile(
optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy']
)生成器の学習のためには二つのモデルを連結したモデルを作成します。ただし、生成器の学習時に識別器の学習をストップする必要があります。
Kerasではモデルの trainable という属性を False にすると、コンパイル後に学習が行われなくなります。コンパイルする必要があるので、先にコンパイルした識別器には影響がないです。
生成器も損失に binary_crossentropy を指定します。
input_layer = Input(shape=(noize_vector_dim,))
discriminator_model.trainable = False
img = generative_model(input_layer)
output_layer = discriminator_model(img)
combined_model = Model(input_layer, output_layer)
combined_model.compile(
optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'],
)(5) モデルの学習
モデルの定義が完了したので、学習を行います。 ただし、GANは学習に時間がかかるため、学習がうまくいっているのか途中経過を確認したいです。
TensorBoardを利用すると学習時の様子が観察できます。 損失を文字で出力して眺めても状況が分かりにくいので、こちらを利用することをお勧めします。
ColaboratoryではTensorBoardを以下のマジックコマンドで起動することができます。
%load_ext tensorboard
%tensorboard --logdir logs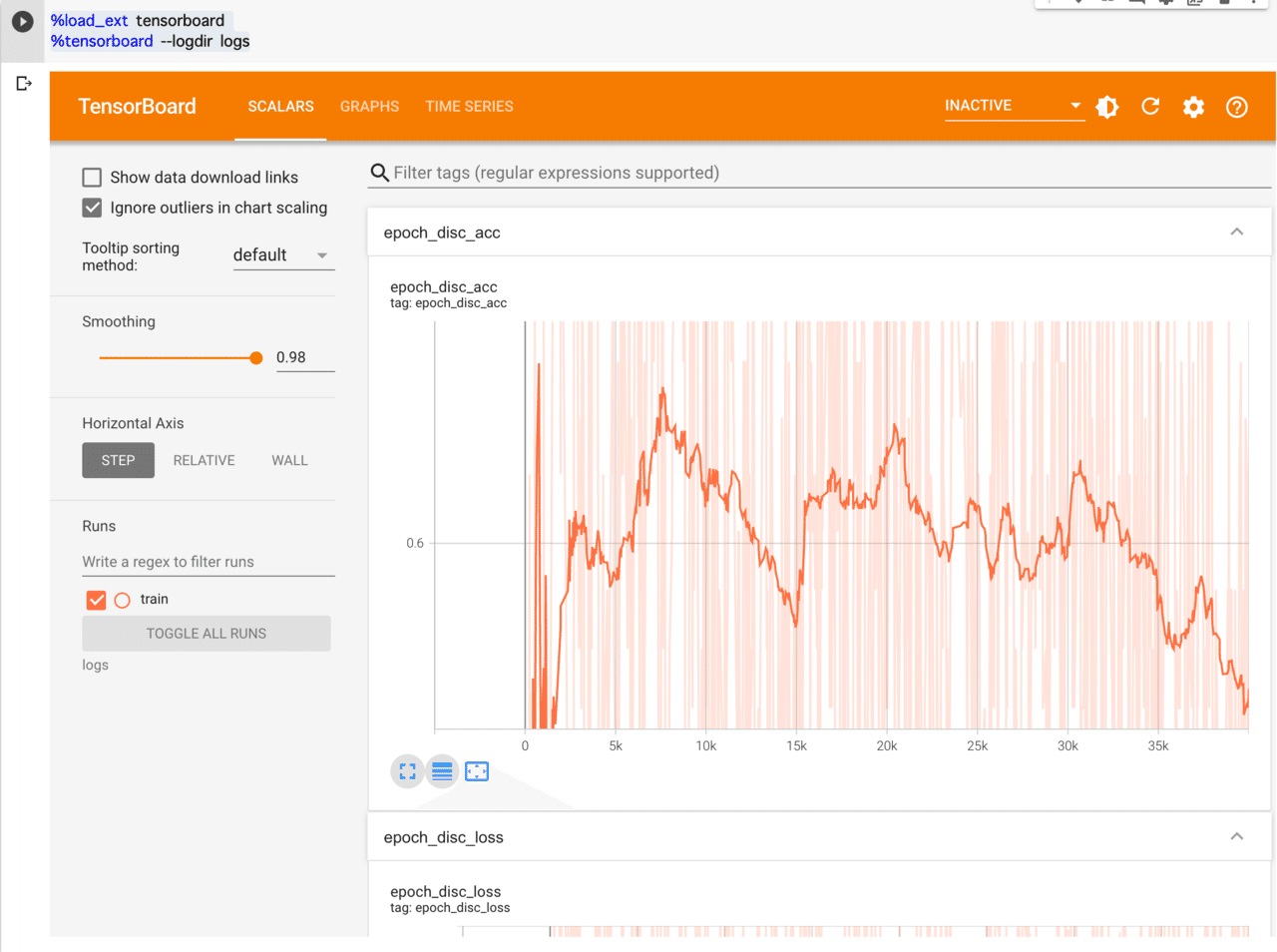
学習のログをTensorBoardを反映するため、 tf.keras.callbacks.TensorBoard を初期化します。
batch_size = 64
from tensorflow.keras.callbacks import TensorBoard
tensorboard = TensorBoard(log_dir="logs", histogram_freq=0, batch_size=batch_size, write_graph=True)各種パラメータと、生成器の入力で必要なランダムベクトルを出力するヘルパー関数を定義します。
batch_size = 64
noize_vector_dim = 100
num_epoch = 50000
def get_random_vector():
return np.random.normal(0, 1, (batch_size, noize_vector_dim))まず、生成器の出力画像を利用して、識別器の学習を行います。その後連結したモデルを用いて生成器の学習を行います。 これを指定したエポック数で学習を繰り返します。
for epoch in range(num_epoch):
# 入力ベクトル
input_vector = get_random_vector()
# 生成画像
fake_image = generative_model.predict(input_vector)
# 生成画像のラベル (全て0)
fake_label = np.zeros((batch_size, 1))
# 本物の画像をサンプリング
index = np.random.randint(0, x_train.shape[0], size=batch_size),
valid_image = x_train[index]
# 本物の画像のラベル (すべて1)
valid_label = np.ones((batch_size, 1))
# 学習のログ
epoch_logs = {}
# 識別器の学習
fake_loss, fake_acc = discriminator_model.train_on_batch(fake_image, fake_label)
valid_loss, valid_acc = discriminator_model.train_on_batch(valid_image, valid_label)
epoch_logs.update({'disc_loss': 0.5*(fake_loss + valid_loss), 'disc_acc': 0.5*(fake_acc + valid_acc)})
# 生成器の訓練
input_vector = get_random_vector()
label = np.ones((batch_size, 1))
logs = combined_model.train_on_batch(input_vector, label, return_dict=True)
epoch_logs.update({'gen_'+key: logs[key] for key in logs})
tensorboard.on_epoch_end(epoch, epoch_logs)
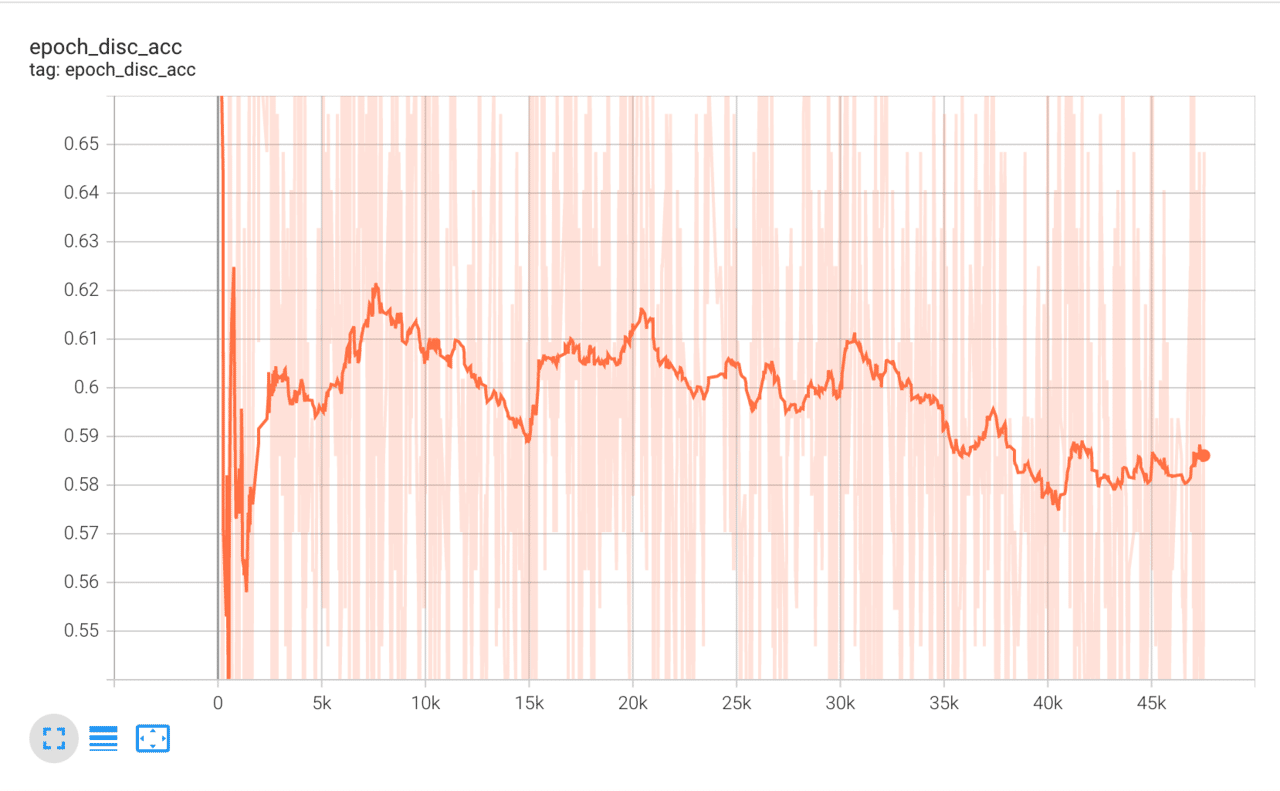
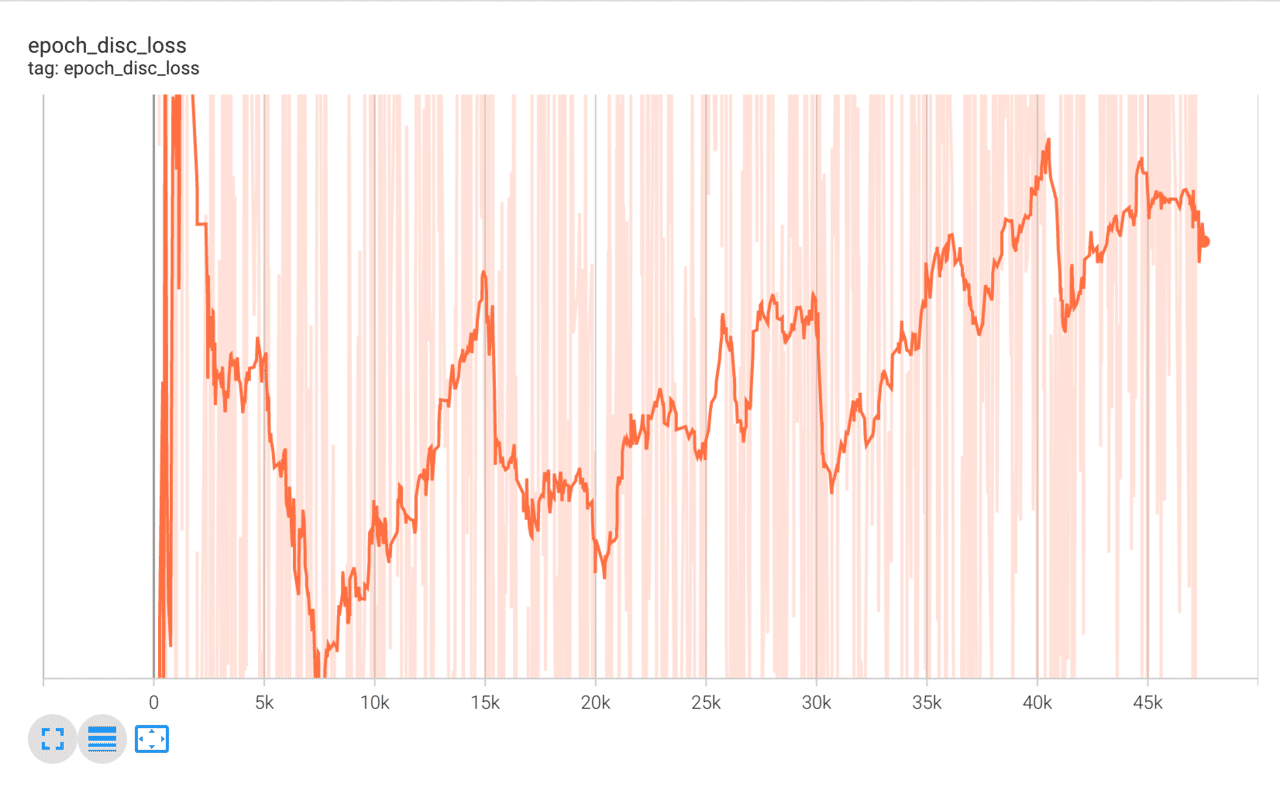
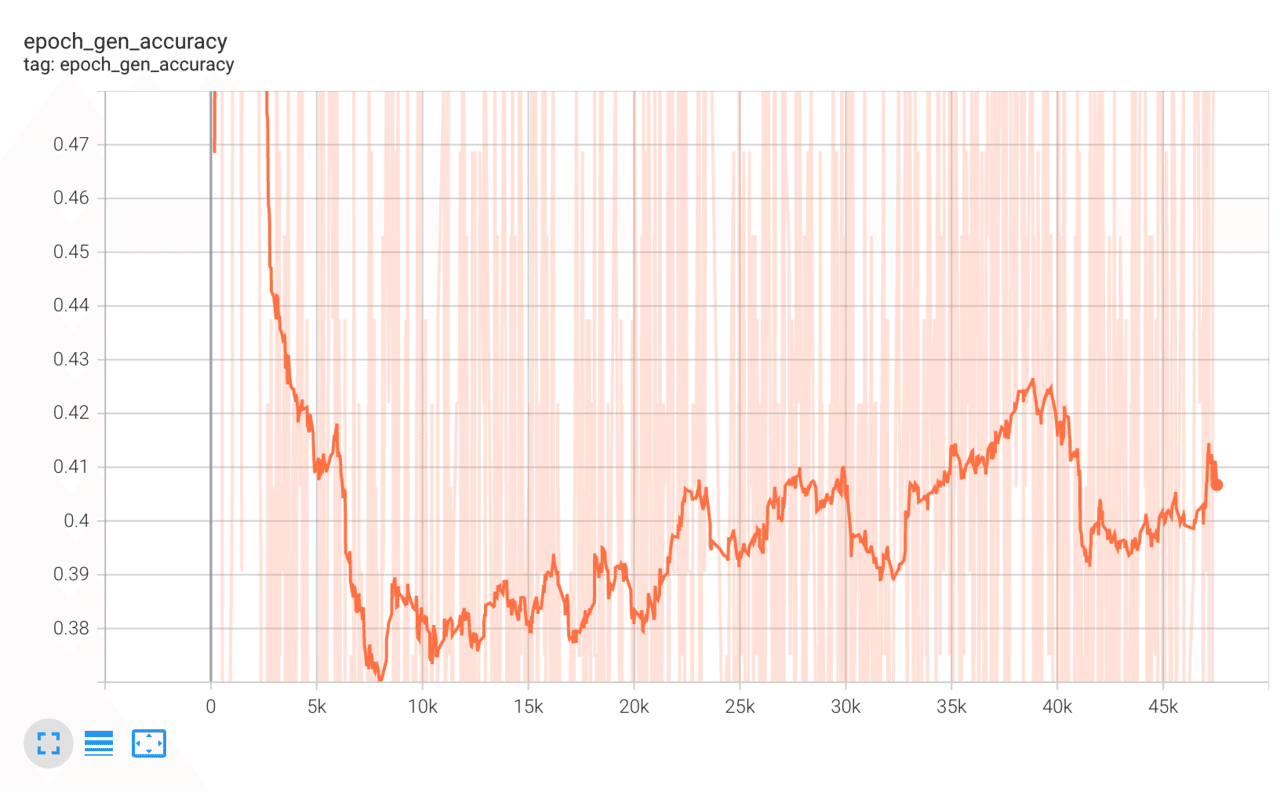
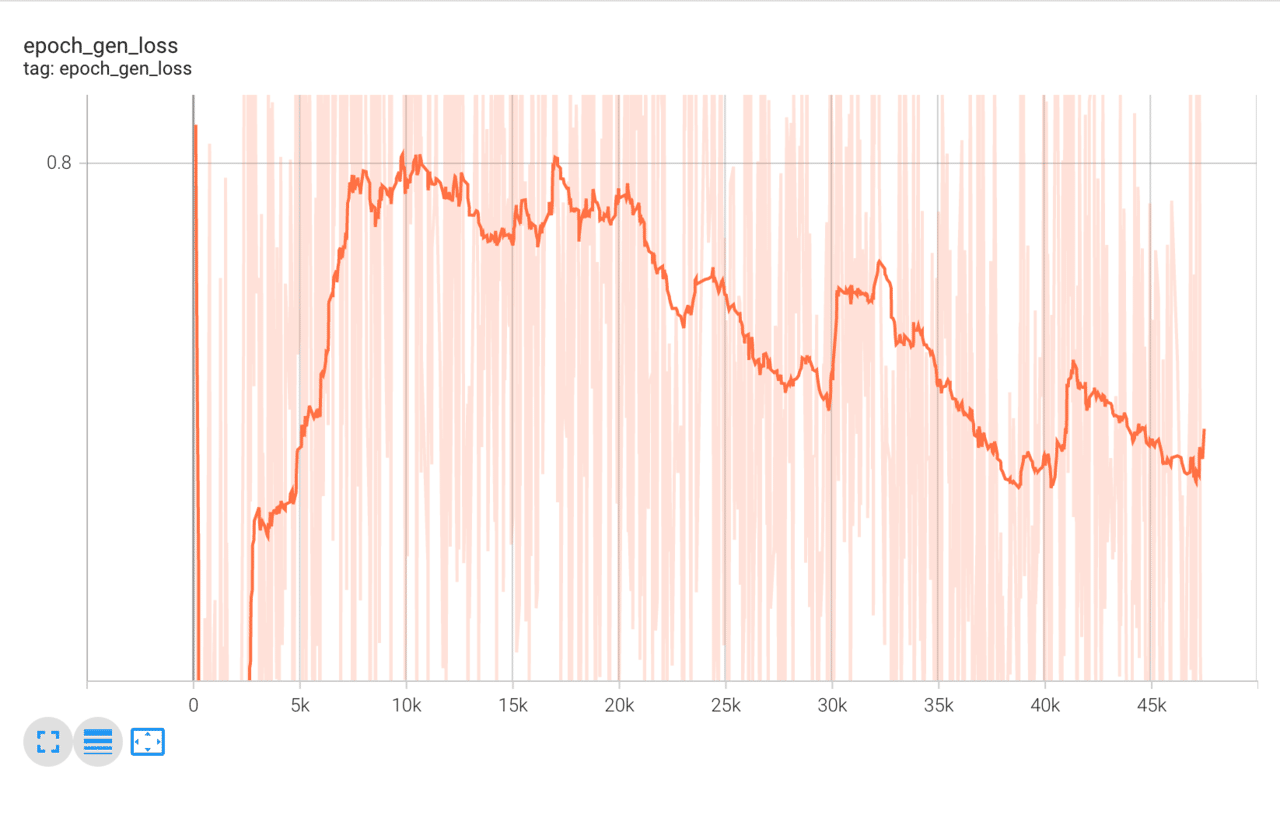
tensorboard.on_train_end(None)学習経過はTensorBoardで確認を行います。lossやaccuracyは激しく振動しているため、Smoothingを「0.95~0.98」など強めにすると分かりやすいです。
以下はそれぞれ、識別器のaccuracy、識別器のloss、生成器のaccuracy、生成器のlossの経過です。accuracyやlossなどが途中で常に一定の値をとってしまったりすると学習が失敗しています。
学習の注意点
入力画像のスケールを「-1~1」に変更することを忘れないようにしましょう。 私は何度も学習が失敗し続けていたのですが、モデルにミスがあるのかと思いずっとハマってました。
また、最適化の学習率で結果が変わるので、失敗する場合は、学習率を変更してみると改善するかもしれないです。
精度が悪い場合は、単にエポック数が足りないかもしれないです。最初は1000~2000程度でなかなか上手くいかないなと悩んでいたのですが、こちらのリポジトリでは18kエポックほど学習していたので学習回数を増やしてみたところ改善しました。
実験結果
以下のように画像をグレースケールで描画します。
for i in range(200):
v = get_random_vector()
y = generative_model.predict(v)
plt.imshow(y[0, :, :, 0] * 0.5 + 0.5, cmap='gray')
plt.figure()50000エポックほど学習した際の出力画像です。手描きの数字画像を緺麗に生成できていると思います。

同じ3という画像をとってみても、色々な出力が行われていることがわかります。