Introduction
This post is for day 16 of the Information Retrieval / Search Technology Advent Calendar 2021. I’ll briefly explain the overall picture of similar image search.
What is similar image search?
Similar image search lets you search with an image as the query and retrieve visually similar images. Unlike conventional text search, which finds documents by text, image similarity search finds targets by visual appearance.
For example, if you’re looking for clothing with a unique pattern, it can be difficult to describe that pattern in words, making text search hard. When appearance matters, image‑based search can be more suitable.

Google Images also supports searching by image, so many readers may have used it before.

Google Images
Recap: full‑text search
In full‑text search, we must retrieve all documents matching a text query. A naive scan over all documents becomes slower as the corpus grows.
To avoid this, we build an index in advance—specifically an inverted index— which maps each term to a list of document IDs, analogous to a book’s back‑of‑book index.

For Japanese text, we perform morphological analysis to split text into tokens and remove particles that aren’t useful for search.
Finally, we rank results by similarity using measures that consider term frequency such as tf‑idf. Apache Lucene is a popular Java library that implements these components. For real systems, we typically rely on Solr or Elasticsearch (both built on Lucene) for clustering, performance, and availability.
How similar image search works
Vectorizing images
In image similarity search, we convert images into vectors so we can compute similarity between vectors (e.g., Euclidean distance or cosine similarity).
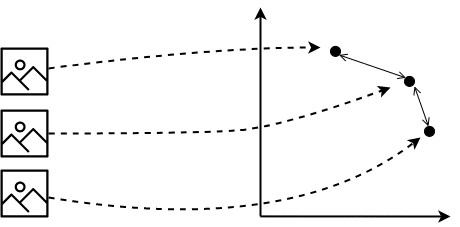
Once images are vectors, we can compute similarity via vector distances
We assume that similar images map to nearby points in the feature space. How we create these vectors is a central design choice.
Feature extraction
With 8‑bit color, each pixel is represented by (R, G, B) in the range 0–255. We could flatten these values to a long vector, but similarity using raw pixels performs poorly due to sensitivity to position shifts and background noise.
Instead, we extract useful features from the image—this is feature extraction. Today, we typically use convolutional neural networks (CNNs) for feature extraction.
CNNs excel at image recognition. With deep learning, they can recognize images at near‑human accuracy and are robust to small shifts, color, or shape variations within a class.
In many applications we want to search by a region within an image. Using object detection, we first detect regions and categories of objects, then extract features only from relevant regions. For example, for face similarity search, we crop faces and extract features from the face area only.

Extract only the face region from the image
To create features suited for similarity, we can use metric learning—more specifically deep metric learning—which trains embeddings so that items of the same class are closer together and different classes are farther apart. Metric learning outputs vectors directly and is effective when there are many classes but few samples per class—exactly the scenario for image search.
Approximate nearest neighbor (ANN)
As with text search, scanning everything and computing similarities at query time does not scale. Practical systems must respond quickly and also search large corpora to provide convincing results.
Thus we use approximate nearest neighbor (ANN) techniques, which trade some accuracy for much better speed. Like inverted indexes for text, ANN builds an index ahead of time.
Representative ANN libraries include Annoy, NMSLIB, Faiss, and NGT. These play a role similar to Lucene in text search.
ANN involves trade‑offs among accuracy, speed, and memory. Choose methods based on data size and latency requirements. For an overview, see Prof. Matsui’s slides “Frontiers of Approximate Nearest Neighbor Search” (Japanese).
Closing
This post outlined how practical similar image search systems work.
As a side note, I previously published a book on similar image search at a tech fair (in Japanese) and plan to release an updated edition in the Izumi Books series. The book walks through implementing an image search system and dives deeper into metric learning and ANN.