はじめに
情報検索・検索技術 Advent Calendar 2021の16日目の記事です。 こちらの記事では類似画像検索に関して、全体像がわかるようにざっと説明したいと思います。
類似画像検索とは
類似画像検索とは、画像をクエリとして類似画像を検索する仕組みのことです。検索として一般的にイメージされるテキスト検索は、目的のドキュメントをテキストによって検索しますが、類似画像検索は画像を使って目的の画像を探し出します。
例えば、独特な模様の服を探し出したいとき、なかなか特徴を言語化するのが難しく、テキストで検索するのが難しいというケースがあるかと思います。このように見た目が重要な場合は類似画像検索の方が適していることがあります。

Google画像検索にも画像で検索する機能があるため、使ったことがある方も多いのではないかと思います。

Google画像検索
全文検索のおさらい
全文検索では、テキストクエリにマッチするドキュメントをもれなく見つけ出す必要がありますが、検索のたびにドキュメント全体を愚直に走査すると、検索対象のドキュメント数が大きいほど、どんどん検索時間がかかるようになってしまいます。
これを防ぐため、事前にインデックス(転置インデックス)を構築することで、検索時間を高速化することができます。本の索引はキーワードごとにページ番号のリストを保持していますが、全文検索も同様にキーワードごとにドキュメントIDのリストを保持しています。

また、日本語のドキュメントのキーワードを作るためには、形態素解析を行なってキーワード単位に分解する必要があります。日本語の文章はどこで区切るか自明ではなく、また検索には不要な助詞などを除去したいためです。
最後に、tf-idfなどでキーワードの出現頻度など考慮して文書の類似度の高い順に検索結果を提示します。これがテキスト検索で行われている処理です。
全文検索ではApache LuceneというJava製の検索ライブラリがよく利用されます。これを利用すると上記の処理を行うことができます。
実際の検索システムではパフォーマンスや可用性のためのクラスタ化などまで行う必要があり、これらを全てを自前で実装するのはかなり大変であるため、普通はApache SolrやElasticsearchなどの全文検索システムを活用して検索システムを構築します。これらは内部的にLuceneを利用しています。
類似画像検索の仕組み
画像のベクトル化
類似画像検索では画像をクエリとして画像を検索します。類似画像検索では画像をベクトルに変換して、ベクトルを用いて画像の類似度を計算できるようにします。
画像をベクトルに変換すると、ベクトル同士のユークリッド距離やコサイン類似度などで類似度を計算できます。
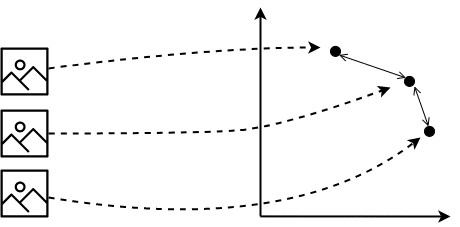
画像をベクトルに変換するとベクトルの距離などで類似度計算が可能になる
ここで前提として、似た画像は近い距離となるようにベクトル化していました。どのように画像をベクトル化するかは類似画像検索において重要なポイントといえます。
特徴抽出 (Feature extraction)
画像が8ビットカラーで表現されているとき、各ピクセルは(赤、緑、青)がどれだけ含まれているか、それぞれ0から255の範囲で表現されます。この数値をまとめて画像のベクトルとすることができます。
しかし、この数値列をそのまま使って画像の類似度計算をしても良い精度にはならないです。検索対象の物体の位置ズレの影響を受けたり、検索対象外の領域がノイズとなってしまうためです。
このような問題に対処するため、画像の中で有用な特徴を抜き出してベクトル化を行います。この処理を特徴抽出と呼びます。近年では画像の特徴抽出は畳み込みニューラルネットワーク(Convolutional Neural Network; CNN)を用いて行われます。
CNNは、画像認識の分野で大きな成果を上げており、ディープラーニングを用いると人間に匹敵する精度で画像を認識できます。CNNを用いて画像認識を行うと、同じカテゴリであれば多少の位置ズレがあったり少々色味や形が違っていても高い精度で認識できます。
画像検索においては、画像の一部領域で検索したいことが多いです。物体検出(Object detection)の技術を用いて、画像に存在する物体の領域やカテゴリを検出することができます。
例えば顔の類似画像検索をしたい場合、顔領域以外は不要な領域なので、顔領域のみ切り取って特徴抽出します。

画像の中から顔領域だけ抜き出す図
類似画像検索に適した特徴ベクトルを作るために、距離学習(Metric Learning)を用いることができます。近年は深層学習技術を使った深層距離学習(Deep Metric Learning)が用いられます。
距離学習を用いると、同じクラスは特徴空間上でより近くに、異なるクラスは遠くになるようなベクトルに変換できるように学習します。距離学習では最終的な出力はベクトルとなります。距離学習はクラス数が多く、サンプル数が少ないケースで有用であると言えます。
類似画像検索では類似度計算のためのベクトルに変換を行いたいため、距離学習が適していると言えます。
近似最近傍探索
類似画像検索もテキスト検索と同様に、検索時に全走査して類似度計算を行うと、検索対象のサイズが大きくなるほど検索時間がかかるようになってしまいます。
実際の検索システムの場合、検索が現実的な時間で終わることは重要です。また、納得感のある結果を得るためには、より多くのデータを検索対象にする必要があります。そもそも似ているデータが存在していなければ、似ている画像を提示することができないからです。
この問題に対処するため、類似画像検索では近似最近傍探索(Approximate Nearest Neighbor; ANN)の技術を利用します。
近似最近傍探索は、ある程度精度を犠牲することで検索処理を高速化します。実際の類似画像検索システムでは、ある程度精度を保ちつつ速度を高速化したいため、近似最近傍探索は必要な技術と言えます。
全文検索では転置インデックスを事前に構築しますが、それと同じように近似最近傍探索でも事前にANNのインデックスを構築します。
代表的なANNライブラリーとして、Annoy、NMSLIB、Faiss、NGTなどがありあります。これらは全文検索でのLuceneに対応するライブラリと言えます。
近似最近傍探索は、精度、速度、メモリーのトレードオフが成立します。用いるデータ数や速度など要件に応じて、手法を選定します。近似最近傍探索の手法については東京大学の松井先生の近似最近傍探索の最前線のスライドが参考になります。
おわりに
この記事では、実際の類似画像検索システムの仕組みについてざっと説明しました。
宣伝になってしまうのですが、類似画像検索についてまとめた本を過去に技術書典で頒布していました。また今後、上記の本の内容を修正&追記した本が技術の泉シリーズから販売される予定です。
こちらの本では、実際に類似画像検索システムを実装しながら理解していく構成になっています。また距離学習や近似最近傍探索についても、もう少し踏み込んで解説する予定です。もし興味がある方はそちらも読んでみていただければと思います!